开云2026世界杯中国官网 AI 芯片里, 委果在“算”的只消八分之一


周末翻一封订阅的英文newsletter,DwarkeshPatel请来MatX的首创东说念主ReinerPope,他想搞了了一块AI芯片里面到底何如运转。
最辛劳的是,Reiner莫得效一句大词。他要了一块黑板,从最小的一个逻辑门初始,一层一层往上搭,直到搭出一整块芯片。
一、最底下,只消三种零件
一块芯片最底层的零件,浅薄到不可想议:与门(AND)、或门(OR)、非门(NOT)。再加上把它们连起来的金属线。仅此辛苦。上千亿个晶体管堆在沿途、连成这些门,即是今天扫数AI的物理载体。
AI芯片绝大部分时期只干一件事:矩阵乘法。而矩阵乘法拆到最小,是一个叫"乘加"(multiply-accumulate)的当作——两个数相乘,再把贬抑累加进一个总数。一次矩阵乘法,即是把这个当作重叠亿万次。
剥到最底,你手机里的语音助手、数据中心里的大模子,全部的智能,都拓荒在天文数字次的"乘一下、加一下"上头。
二、用门搭一个乘法器,和那条决定一切的正常律
Reiner在黑板上手算了一个四位数乘四位数。
先把一个数的每一位,去乘另一个数——每一次相乘,即是一个与门(两个比特都是1才输出1)。四位乘四位,要十六个与门,获得十六个中间贬抑。
难的是把它们加起来。这里他请出了芯片上"最大"的一种门:全加器(fulladder)。它作念的事朴素得可人——把归并列的三个比特加起来,输出两个比特,无非是数一数这一列有几个1,再用二进制写出来——跟小学列竖式里"满二进一"是一趟事。三进两出,是以也叫3→2压缩器。
把这些全加器层层叠起来,每次吃掉一列里的三个数、吐出两个,一直压到只剩一个数,乘法就算结束。这套尺度作念法叫Dadda乘法器。
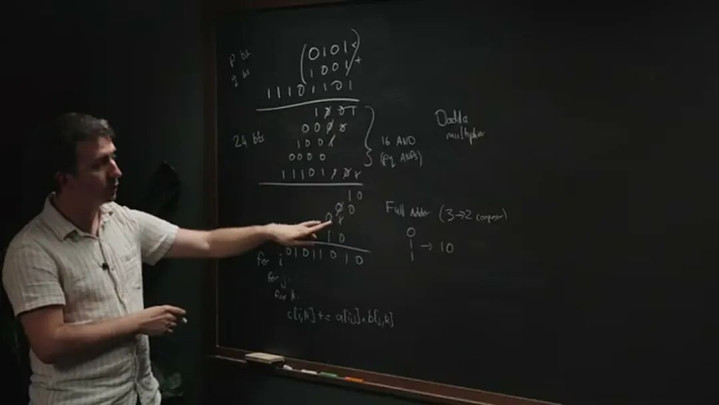
Reiner在黑板上手推乘加:16个与门生成中间贬抑,再用全加器(3→2压缩器)层层乞降,这即是Dadda乘法器
算一笔账:一个p位乘q位的乘法器,要用掉p×q个与门和p×q个全加器。盯住这个p×q——它跟位数的正常成正比。而一个地说念的加法器,只消一排全加器,正比于位数p。
愣一下的场所在这里:乘法比加法贵得多,况兼乘法器的面积,是随位数正常扩张的。这条不起眼的正常律,接下来会引爆一切。
三、精度的魔法:为什么砍一半位数,能快近四倍
这几年总听到FP8、FP4这种词,说的是芯片用几位精度去示意一个数。
直观上,精度从8位砍到4位,速率该快一倍。但记取上一节那条正常律:面积随位数正常走。位数减半,乘法器面积不是减半,是减到四分之一。
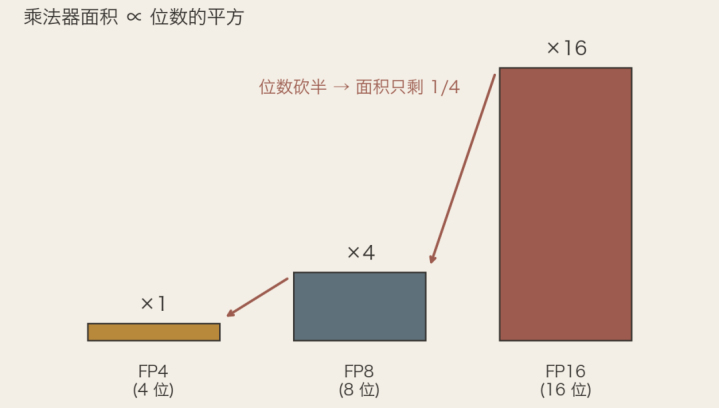
乘法器面积随位数的正常扩张:精度从FP16砍到FP8再到FP4,面积每砍一档就缩到四分之一
是以英伟达从B300这一代初始,在家具规格里改了口径:FP4的算力是FP8的三倍,而不再是曩昔的两倍。Reiner说,按正常律本该是四倍,能作念到三倍依然很接近了。
这一下点透了一件大事:神经收集之是以能用这样低的精度跑得这样好,最根柢的原因即是这条正常律。低精度从来不是"对付着用",而是把"足够的精度"这件不菲的奢华主动扔掉,换回成倍的速率。够用,自身即是一种极致的高效。
四、芯片委果的资本,不在算,在搬
到这里你好像觉得,芯片的面积都花在乘法器上了。适值相背。
把乘加单元装进一个旧式的处理器中枢:独揽有个寄存器堆(registerfile),存着一小批数;每次从里面取三个数,算一下乘加,再把贬抑写且归。
问题出在"取第三号寄存器里阿谁数"这个当作。写轨范的东说念主一排代码就处理,理所诚然。可在硬件上,"从一堆里放浪挑一个出来"自身即是个啰嗦电路,叫多路给与器(mux):你得把每一个候选都用门过一遍,再汇到沿途,才智拣出要的阿谁。一个n选一、p位宽的mux,要n×p个与门加一堆或门。
一个乘加要三个输入,就要三个这样的mux。Reiner把账一摆:寄存器堆只消八格时,光是把三个数挑出来送进去,要二十四份门的资本;而委果作念乘法的部分,只消四份。

左边是Dadda乘法器,右边是寄存器堆经mux喂给乘加单元(×+)。委果算的电路很小,挑数据、搬数据的电路很大
这是全片最关节的一击:在阿谁中枢里,简直八分之七的面积和功耗,都花在把数据搬进搬出寄存器堆上,委果用来缠绵的只占八分之一凹凸。光挑数那三个mux就已是二十四比四、约七分之一,再算上寄存器自身的存储和贬抑写回,搬运那侧只多不少。咱们觉得芯片在拚命算,其实它大部分时期在拚命搬。
这一条,是解析背面一切的钥匙。整部AI芯片进化史,骨子上即是一场"少搬少许"的干戈。
五、越搬越远越贵:存储的层级,和细则的延伸
搬运的代价,随距离层层放大。
离缠绵最近的是片上的寄存器和SRAM,快,但小,况兼极占面积;远少许是片外的DRAM、HBM,容量大得多,却慢得多——CPU的缓存比主存快上两个数目级,莫得缓存,轨范会慢一百倍。
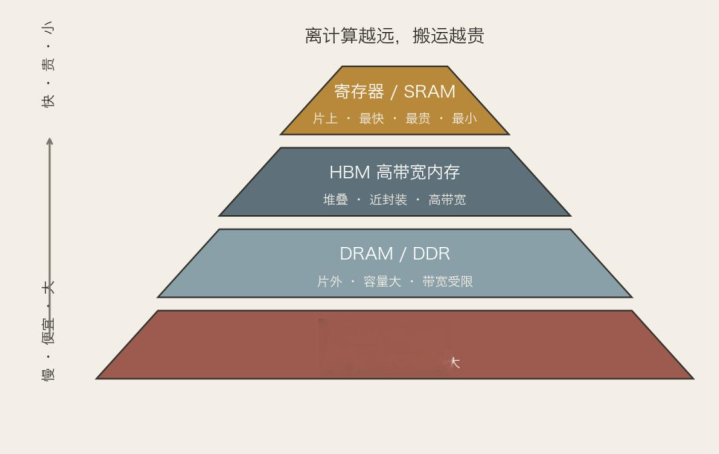
芯片的存储层级:越往上越快、越贵、越小,越往下越慢、越低廉、越大。离缠绵越远,搬运越贵
带宽(bandwidth)说到底是什么?是你能同期拉几许根线收支。而线是要占面积的。Reiner那句话很高超:带宽就等于芯单方面积。这即是为什么内存带宽恒久是瓶颈——它不是不愿给你更多,是每一根线都在和缠绵单元抢地皮。
这里还藏着一个分叉。CPU用缓存(cache),由硬件自动决定一个数在不在缓存里,好用,但你预先不知说念此次探望要花多久,全看独揽还跑着什么轨范。TPU这类芯片改用便笺存储(scratchpad):用一种请示明确读片上,用另一种请示明确读HBM,全交给软件安排。
反直观的适值在这里:主动消除"贤人的缓存",换来的是细则的延伸。你能精准算出每个数什么时候到。这即是高频走动偏疼FPGA、TPU在中枢里也坚抓细则延伸的原因——在需要掐着纳秒作念事的花式,可瞻望比"平均更快"值钱得多。
六、脉动阵列:少搬少许的艺术
既然搬最贵,最贤人的办法即是尽量不搬。
矩阵乘法有个奥密的性质——阿谁权重矩阵,不错在很长一段时期里保抓不动。于是有了脉动阵列(systolicarray):把权重平直焊在缠绵单元的原地,让输入数据像水一样从一头流进、另一头流出,一份权重反复用上成百上千次。
连权重何如加载都很肃穆:不走不菲的宽总线,而是逐步"涓流"灌进去,一个时钟挪一格。归正只灌一次,不错慢,慢就能省线。
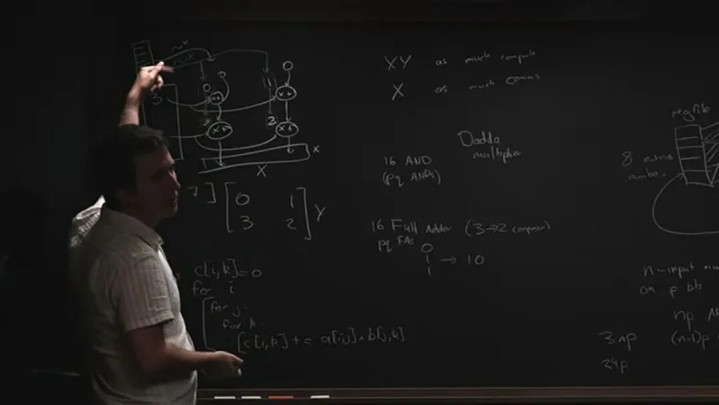
脉动阵列:权重固定在网格里不动,数据从边高尚进流出。谷歌TPU的矩阵单元即是它;英伟达的TensorCore也用了归并个念头
省钱的奥秘一句话就能说清:阵列越大,每从寄存器堆里读一次,就聪颖越多的活,那笔固定的搬运资本就摊得越薄。老一代TPU把这个阵列作念到256×256这样大一派,是现在已知最省的矩阵乘电路。谷歌TPU里的矩阵单元,自身即是一块脉动阵列;英伟达从Volta那代引入的TensorCore,底层亦然归并个念头——仅仅没作念成严格的脉动结构。
七、时钟、活水线,和"快不等于多"
上千亿个晶体管要协同职责,何如对王人节律?
谜底是时钟。神圣每一纳秒,全芯片扫数电路沿途停一下、跳到下一步,整王人整齐,像一支王人步走的雄兵。这一拍,即是一个时钟周期。

黑板右上的时钟(CLK):信号同步两头的寄存器,中间夹着一团逻辑云——这团逻辑必须不才一拍敲响之前算完
想跑得更快,比如从1GHz提到2GHz,就得保证每一段逻辑都能不才一拍敲响之前算完。常用技能叫活水线寄存器插入:把一长段逻辑从中间切一刀、塞个寄存器进去,每段变短,时钟就能翻倍——代价是多占了存储面积。
那能弗成一直切下去?切到极致,一个门加一个寄存器成一个环,时钟能飙到五六GHz。可这时简直扫数面积都花在寄存器上了,每一拍委果干的活少得惘然。
这里有个好多东说念主想反的论断:时钟快,不等于干得多。你不错有很低的延伸,却只消很低的抵赖——这和大模子推理时把batchsize调小是归并趟事:单个用户拿到下一个词很快,但一小时处理的总词数反而更少。最辣手的是那种我方绕回我方的反应电路,你没法璷黫从中间切一刀,不然就改变了缠绵自身。整块芯片的时钟上限,频频就卡在这种环上。
八、FPGA与ASIC:生动是要付费的
一样一个电路,焊死了作念成专用芯片(ASIC),照旧作念成现场可改的FPGA?
ASIC第一颗要走一整套流片(tape-out),三千万好意思元起步;可一朝量产,单元资本和能效要好上十倍独揽。FPGA第一颗只消一万好意思元,代价是又慢又费电。是以FPGA的用武之地,是那种每个月就要改一次、又条目延伸极细则的活,比如高频走动——你不想为每次改变都付一次流片的钱。
FPGA何如作念到"现场可编程"?靠两样东西:寄存器负责存,查找表(LUT)负责当门用。一个LUT有四位输入、一位输出。四位输入一共十六种组合,把每种组合对应的输出列成一张十六行的真值表存起来——你想要它当与门,就填与门那张表;想要异或门,就填异或门那张表。
精妙也跋扈都在这少许:所谓"可编程的门",骨子即是一张随时能改写的真值表。但代价惊东说念主:这样一个LUT,里面其实是个十六选一的mux,要三十二个门,开云世界杯官网(中国)去终了一个底本三个门就能搭好的电路。生动性的全部资本,即是把每一个门都用mux包起来——Reiner说,是"一齐mux到底"。这即是FPGA比ASIC贵十倍的来处。

FPGA的真面庞:寄存器和查找表(LUT)被一大堆mux连在沿途,橙色是现场编程出来的连线。一齐mux到底
九、一整块芯片:GPU、TPU,和MatX想作念的事
把这些零件拼成一整块芯片,GPU和TPU走了两条不同的路。
GPU是一整片铺满了简直一样的小单元(叫SM),中间夹一块分享的L2缓存,规规整整的网格。TPU则粗粒度得多:几块很大的矩阵单元,中间配一个向量单元。

上头是GPU——一格格简直调换的小单元SM平铺,中间一块L2;底下是TPU——几块大矩阵单元(MXU)夹着一个向量单元
Reiner一句话戳破了两者的联系:GPU其实即是把许许多多个微缩版的小TPU,平铺在一整块芯片上。每个SM里的tensorcore,约等于一个减轻的矩阵单元。
接下来是全片最优雅的收束:莫得谁悉数更好。TPU那种大块头,能把寄存器堆的固定资本摊得更薄,是以阵列能作念得更大、更省;但向量单元和矩阵单元之间的数据,只可挤过两条界限线。GPU单元小、到处都是向量单元,数据能走十六条线,更生动、跨的距离也更短、更省电——前提是你别跨出单个SM。规整省资本但固执,细碎够生动但搬运贵,又一次回到"算与搬"的衡量。
那MatX想作念什么?Reiner公开讲过一个"可拆分的脉动阵列":既能当一块大阵列用,也能拆成若干小阵列——想同期要TPU的大而省,和GPU的小而活。说到砍面积,有个现成的例子:CPU里有一大块有益猜"下一条请示往哪跳"的分支瞻望器,而GPU干脆把它通盘扔掉,省下的面积全堆给缠绵——这恰是当年GPU甩开CPU的关节之一。MatX想顺着这条路再走一步:保留GPU那种小阵列加SRAM环绕的生动,再把为撑抓CUDA架构而设、跑AI却用不上的那些电路也一并免却。
想象一块芯片,到头来简直全是尺寸的弃取:阵列作念多大,寄存器堆配多大,FP4给几许、FP8给几许。莫得尺度谜底,全看你赌哪一种负载会赢。
十、旨趣一通,半导体的几条干线也就了了了
看懂了上头这些,再回头看这几年半导体最热的那些叙事,会有一种霎时通透的嗅觉。它们简直都在回复归并个问题:何如把"搬"这件事作念得更低廉。
先说存储这条线。著作里阿谁层级——寄存器、SRAM、DRAM、再到最外面的闪存——其实即是一张半导体的产业舆图。最外层的NANDFlash最慢最低廉,3DNAND这几年比的是"层数",骨子是在一样一块面积上往天上堆更多存储单元,越堆越高,单元容量越低廉。可一朝想通了"搬运比容量金贵",你就不会再用"越大越好"去解析存储——委果卡脖子的从来不是能存几许,是能多快地搬进搬出。
DRAM是中间那一层,快得多,但它的带宽被死死摁在一个物理上限上:你能从一块芯片引出几许根线(引脚)。三星、SK海力士、好意思光这三家的竞争,说到底即是在这条物理红线下,谁能榨出更多带宽。
于是有了HBM(高带宽内存),这一轮AI行情里最硬的一个词。它的想路浅薄得惊东说念主:单片引脚不够,那就把好几片DRAM像盖楼一样叠起来,再用一种叫TSV(硅通孔)的技术,在芯片里面平直买通上基层,一次性引出极宽的总线,带宽一举升迁五到十倍。读懂了"搬运是瓶颈",你就读懂了为什么HBM是AI时期最关节的一块拼图——它正面解决了阿谁最贵的问题。SK海力士因为最早把HBM喂进英伟达,一跃成了整条AI芯片供应链的咽喉。
再往下一层是封装。数据搬得越近越省,那索性别让GPU和HBM隔着老远——台积电的CoWoS,即是把缠绵芯片和一摞HBM放到归并块基板上牢牢挨着,把搬运的距离压到最短。chiplet(小芯片)亦然归并个景仰:与其造一整块宏大、良率堪忧的芯片,不如拆成几块小的再拼起来。先进封装这两年这样金贵,根子照旧那句话——近,即是省。
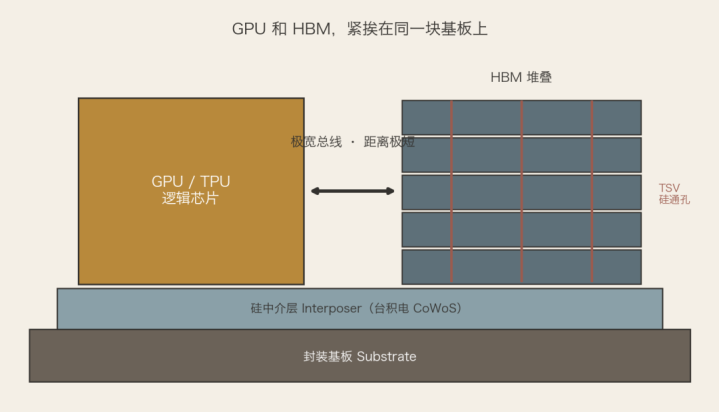
HBM把多片DRAM用TSV硅通孔垂直堆叠,再靠台积电CoWoS封装和GPU挤在归并块基板上,把最贵的那段搬运距离压到最短
终末回到MatX那条线。ASIC的全部赌注,即是著作里反复出现的阿谁衡量:当负载足够细则——比如通盘寰球都在跑Transformer——就不错像TPU那样,砍掉GPU为"应酬下一种未知算法"而预留的生动性,把省下来的面积全部还给缠绵。赌对了,成果碾压;赌错了,下一个架构一来就得推倒重练。
这些干线,莫得一条是捏造热起来的。把芯片里面那说念物理题看显明,产业舆图上的泰半个热门,都能我方对上号。
十一、顺着归并条旨趣,往前看
AG百家乐APP中国官方下载一样这套景仰景仰,不单能讲明注解曩昔,也能拿战斗前看。顺着它推,下一批瓶颈和契机落在哪,见解其实相称了了。
第一步,让数据走垂直见解。芯片里面的搬运距离,被二维平面的布局死死按住——再相邻的两个模块,横着走亦然毫米级。可如若把逻辑层和存储层像盖楼一样垂直叠起来(3DIC),数据从上一层穿到下一层,只走微米级的距离,比横着快上几个数目级。下一步是把缠绵逻辑也叠上去,让内存和逻辑面临面(logic-on-memory)——台积电的SoIC、英特尔的Foveros都在作念这件事。委果的拦路虎是散热:叠得越高,夹在中间那几层的热越难导出去。
第二步,干脆别搬。最透顶的省搬运,是让缠绵平直发生在数据待的场所。脉动阵列依然是这个念头的雏形——权重不动,数据流过。把它推到终点,即是存内缠绵(PIM):平直在内存阵列里作念乘加,数据一步都不挪。三星和SK海力士依然在HBM里试着塞进缠绵单元。难点在于存储工艺和逻辑工艺天陌生歧,良率和精度都是坎。但见解不会错——只消"搬"照旧最贵的那件事,"不搬"就恒久有招引力。
第三步,拼起来之后,谬误成了新瓶颈。上一节阿谁拆成小芯片再拼的作念法,会坐窝撞上归并条铁律:芯片与芯片之间的搬运,成了新的最贵活动。于是谁界说了芯片间互连的尺度,谁就掐住下一代的咽喉——UCIe这类怒放互连之争,抢的恰是"芯片之间那段搬运"的语言权。
再往前一步,是改写"搬"和"算"的物理自身。上头几步都还在数字电路的框架里腾挪。再往根上走,是换掉电路的物理终了:像忆阻器(memristor)这样的新器件,能在归并个物理点上既存数据又作念缠绵,用模拟的容貌一次算完一整列乘加——把"存"和"算"合二为一,连"搬"这个当作都取消掉。这还很早,工艺、噪声、可量产性一个都没解决。但它指向的是末端:当存与算不再分家,今天这套层级与搬运的全部苦恼,可能从根上消逝。
这些见解,莫得一个是注定的赢家。但它们都朝着归并处去——搬运的终点。
十二、把这把尺子,量一量中国
这套旨趣最实用的场所,是给了咱们一把尺子:不再抵赖说"中国芯片逾期几年",而是分维度看——到底落在"算"上,照旧"搬"上。
先说被反复念叨的制程。EUV光刻机被卡,中芯海外量产大致停在7纳米这档,再往下莫得高产量的路。制程决定一样一块面积能塞几许晶体管,平直对应"算"的密度。这一刀,落在最疼的场所。
可别忘了全片那记最重的一击:一个中枢里委果在算的只消八分之一,剩下八分之七都在搬。制程逾期,逾期的主如若那八分之一。把尺子转到"搬"这一侧,画面坐窝复杂起来。
精度是第一个回转。那条正常律——位数砍半,乘法器面积缩到四分之一——意味着一颗7纳米芯片把精度压到FP8,单元面积的抵赖能靠近一颗5纳米跑FP16的。低精度是条简直不挑制程的近路:DeepSeek平直用FP8覆按,骨子是拿算法的贤人赎制程的逾期。
封装是第二个。"近即是省"这条铁律适值不依赖最先进的光刻。把几块锻真金不怕火工艺的小芯片拼起来(chiplet)、用先进封装挤到一块基板上,是绕开EUV的边门。华为把两颗缝成一颗用,走的即是这条路——这是现在追得最紧的一段。
最深的那说念沟是HBM。带宽即是面积,搬运是终极瓶颈,而HBM恰是这门工夫的王冠。SK海力士靠它扼住整条供应链,中国的长鑫才刚起步,差着好几代。制程还能用封装和精度绕,HBM这说念墙却莫得边门。
终末是阿谁赌局。GPU留着生动性应酬未知算法,ASIC把生动性砍掉、面积全还给缠绵。当制程本就逾期,赌一个细则的负载——全寰球都在跑Transformer——把省下的晶体管全堆到算力上,反而更合算。华为昇腾赌的恰是这个,代价也写在原文里:赌错一代架构,就得推倒重练。
而ASIC这条路,恰可口中国的一项所长。专用芯片的命门是两件事:赌对负载、再把电路一遍遍打磨到极致——后者是典型的东说念主海工程。中国每年涌出的芯片与AI工程师数以十万计,东说念主力资本只消硅谷的零头,"为每一种负载有益作念一颗"这种又费东说念主又费时的活,在这里反而办得起。何况赌哪种负载,本就要海量确凿场景去校准——而汉文互联网的数据与期骗密度,给的恰是这个。
收起尺子,论断既不悲不雅也不粗鲁:中国在"算"的最前沿逾期一档,但芯片的泰半山河在"搬",而"搬"这一侧裂成了几块——封装能追,低精度能补,HBM是真沟。
从一个门,到一整块芯片
两个多小时,Reiner从一个与门讲到一整块TPU开云2026世界杯中国官网,中间莫得一句空论。这寰球上最复杂的造物之一,底层逻辑朴素得不像话。它一辈子只在作念两件事——算,和搬。而扫数的小巧,扫数的代际之争,全在怎样让"算"多少许,让"搬"少少许。